DTA-Nachrichten vom 3. Februar 2017Dokumente aus dem Deutschen Textarchiv sind nun mit den Voyant Tools analysierbar
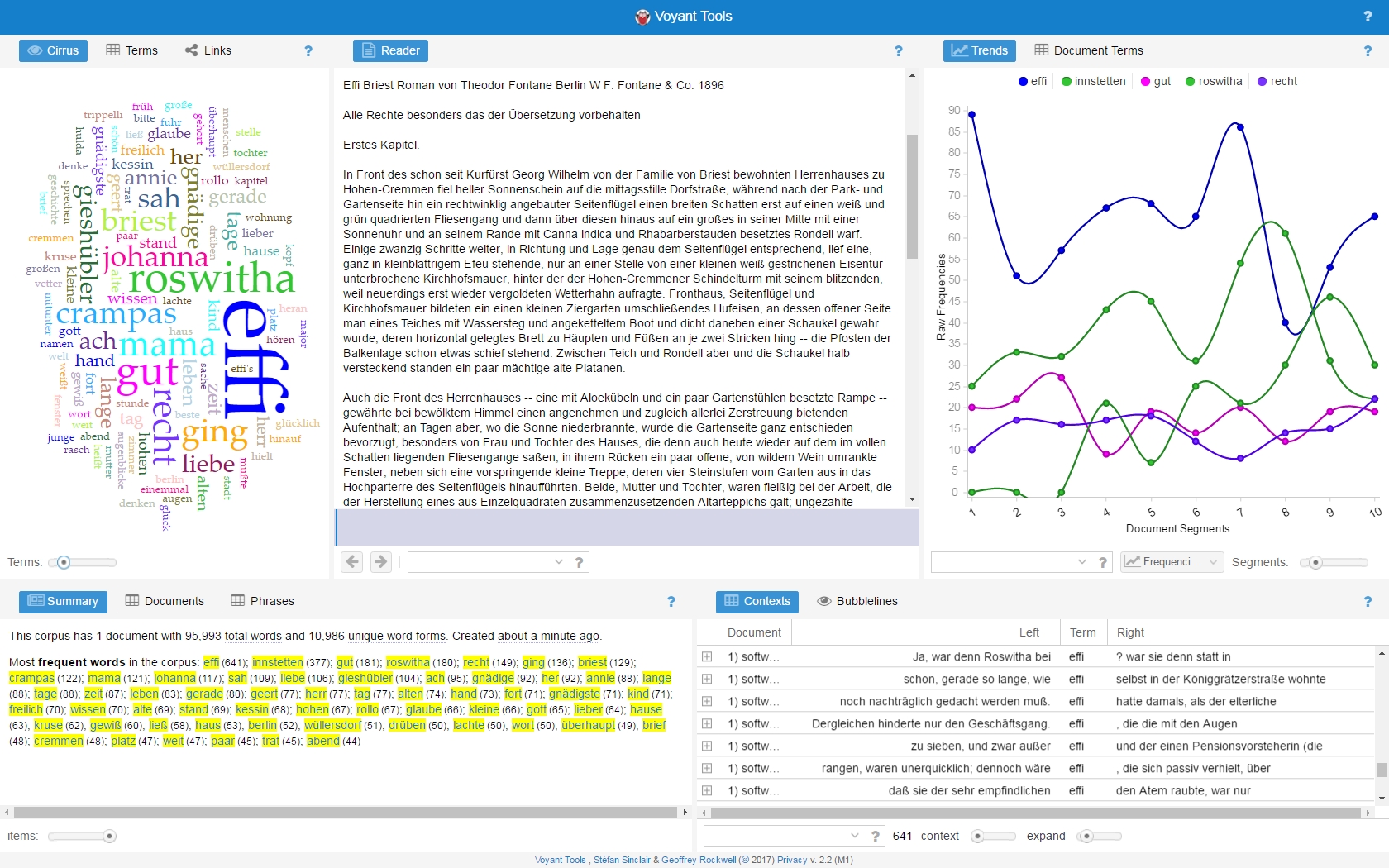 Die XML-Volltexte aus dem DTA werden eigens zu diesem Zweck und ohne weiteren nutzerseitigen Aufwand präprozessiert, um eine nahtlose Verwendung und optimale Analyseergebnisse gewährleisten zu können. Zur Analyse mit Voyant stellt das Deutsche Textarchiv drei spezielle XML-Fassungen zur Verfügung:
Die Verbindung des Deutschen Textarchivs mit Voyant ist im Menü zu jedem DTA-Text unter "Ansichten" zu finden. Dabei kann zwischen den oben beschriebenen drei Varianten gewählt werden. [1] Ausführliche Informationen zur Nutzung des Voyant-Tools finden Sie in der Dokumentation dieses Werkzeuges. [2] Alle angebotenen XML-Fassungen beruhen auf dem DTA-Basisformat (DTABf) und entsprechen demgemäß den Richtlinien der Text Encoding Initiative (TEI). Jedem Text wurde im TEI-Header ein Zitationshinweis sowie eine kurz gefasste Erläuterung zur Erzeugung der jeweiligen Fassung hinzugefügt. Die XML-Fassungen werden vollautomatisch erstellt und können aufgrund dessen, insbesondere bei der Analyse historischer Schreibweisen und der Lemmatisierung, auch Fehler enthalten. Die XML-Fassungen werden bei jedem Abruf eigens erzeugt, weshalb zu unterschiedlichen Zeitpunkten erzeugte Fassungen voneinander abweichen können. von Christian Thomas, 3. Februar 2017 |

Insbesondere im Hinblick auf die §§ 86a StGB und 130 StGB wird festgestellt, dass die auf diesen Seiten abgebildeten Inhalte weder in irgendeiner Form propagandistischen Zwecken dienen, oder Werbung für verbotene Organisationen oder Vereinigungen darstellen, oder nationalsozialistische Verbrechen leugnen oder verharmlosen, noch zum Zwecke der Herabwürdigung der Menschenwürde gezeigt werden. Die auf diesen Seiten abgebildeten Inhalte (in Wort und Bild) dienen im Sinne des § 86 StGB Abs. 3 ausschließlich historischen, sozial- oder kulturwissenschaftlichen Forschungszwecken. Ihre Veröffentlichung erfolgt in der Absicht, Wissen zur Anregung der intellektuellen Selbstständigkeit und Verantwortungsbereitschaft des Staatsbürgers zu vermitteln und damit der Förderung seiner Mündigkeit zu dienen.
2007–2024 Deutsches Textarchiv, Berlin-Brandenburgische Akademie der Wissenschaften.
Kontakt: redaktion(at)deutschestextarchiv.de. |
|
